Edited on May 16th, 2013: fixes due to M. Chiarandini
On the blackboard, to solve small Integer Linear Programs with 2 variables and less or equal constraints is easy, since they can be plotted in the plane and the linear relaxation can be solved geometrically. You can draw the lattice of integer points, and once you have found a new cutting plane, you show that it cuts off the optimum solution of the LP relaxation.
This post presents a naive (textbook) implementation of Fractional Gomory Cuts that uses the basic solution computed by CPLEX, the commercial Linear Programming solver used in our lab sessions. In practice, this post is an online supplement to one of my last exercise session.
In order to solve the “blackboard” examples with CPLEX, it is necessary to use a couple of functions that a few years ago were undocumented. GUROBI has very similar functions, but they are currently undocumented. (Edited May 16th, 2013: From version 5.5, Gurobi has documented its advanced simplex routines)
As usual, all the sources used to write this post are publicly available on my GitHub repository.
The basics
Given a Integer Linear Program in the form:
it is possible to rewrite the problem in standard form by adding slack variables:
where is the identity matrix and is a vector of slack variables, one for each constraint in . Let us denote by the linear relaxation of obtained by relaxing the integrality constraint.
The optimum solution vector of , if it exists and it is finite, it is used to derive a basis (for a formal definition of basis, see [1] or [3]). Indeed, the basis partitions the columns of matrix into two submatrices and , where is given by the columns corresponding to the basic variables, and by columns corresponding to variables out of the base (they are equal to zero in the optimal solution vector).
Remember that, by definition, is nonsingular and therefore is invertible. Using the matrices and , it is easy to derive the following inequalities (for details, see any OR textbook, e.g., [1]):
where the operator is applied component wise to the matrix elements. In practice, for each fractional basic variable, it is possible to generate a valid Gomory cut.
The key step to generate Gomory cuts is to get an optimal basis or, even better, the inverse of the basis matrix multiplied by and by . Once we have that matrix, in order to generate a Gomory cut from a fractional basic variable, we just use the last equation in the previous derivation, applying it to each row of the system of inequalities
Given the optimal basis, the optimal basic vector is , since the non basic variables are equal to zero. Let be the index of a fractional basic variable, and let be the index of the constraint corresponding to variable in the equations , then the Gomory cut for variable is:
Using the CPLEX callable library
The CPLEX callable library (written in C) has the following advanced functions:
- CPXbinvarow computes the i-th row of the tableau
- CPXbinvrow computes the i-th row of the basis inverse
- CPXbinvacol computes the representation of the j-th column in terms of the basis
- CPXbinvcol computes the j-th column of the basis inverse
Using the first two functions, Gomory cuts from an optimal base can be generated as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
The code reads row by row (index i) the inverse basis matrix multiplied by (line 7),
which is temporally stored in vector z,
and then the code stores the corresponding Gomory cut in the compact matrix given by vectors rmatbeg, rmatind, and rmatval (lines 8-15).
The array b_bar contains the vector (line 21). In lines 26-27, all the cuts are added at once to the current LP data structure.
On GitHub you find a small program that I wrote to generate Gomory cuts for problems written as . The repository have an example of execution of my program.
The code is simple only because it is designed for small IPs in the form . Otherwise, the code must consider the effects of preprocessing, different sense of the constraints, and additional constraints introduced because of range constraints.
If you are interested in a real implementation of Mixed-Integer Gomory cuts, that are a generalization of Fractional Gomory cuts to mixed integer linear programs, please look at the SCIP source code.
Additional readings
The introduction of Mixed Integer Gomory cuts in CPLEX was The major breakthrough of CPLEX 6.5 and produced the version-to-version speed-up given by the blue bars in the chart below (source: Bixby’s slides available on the web):
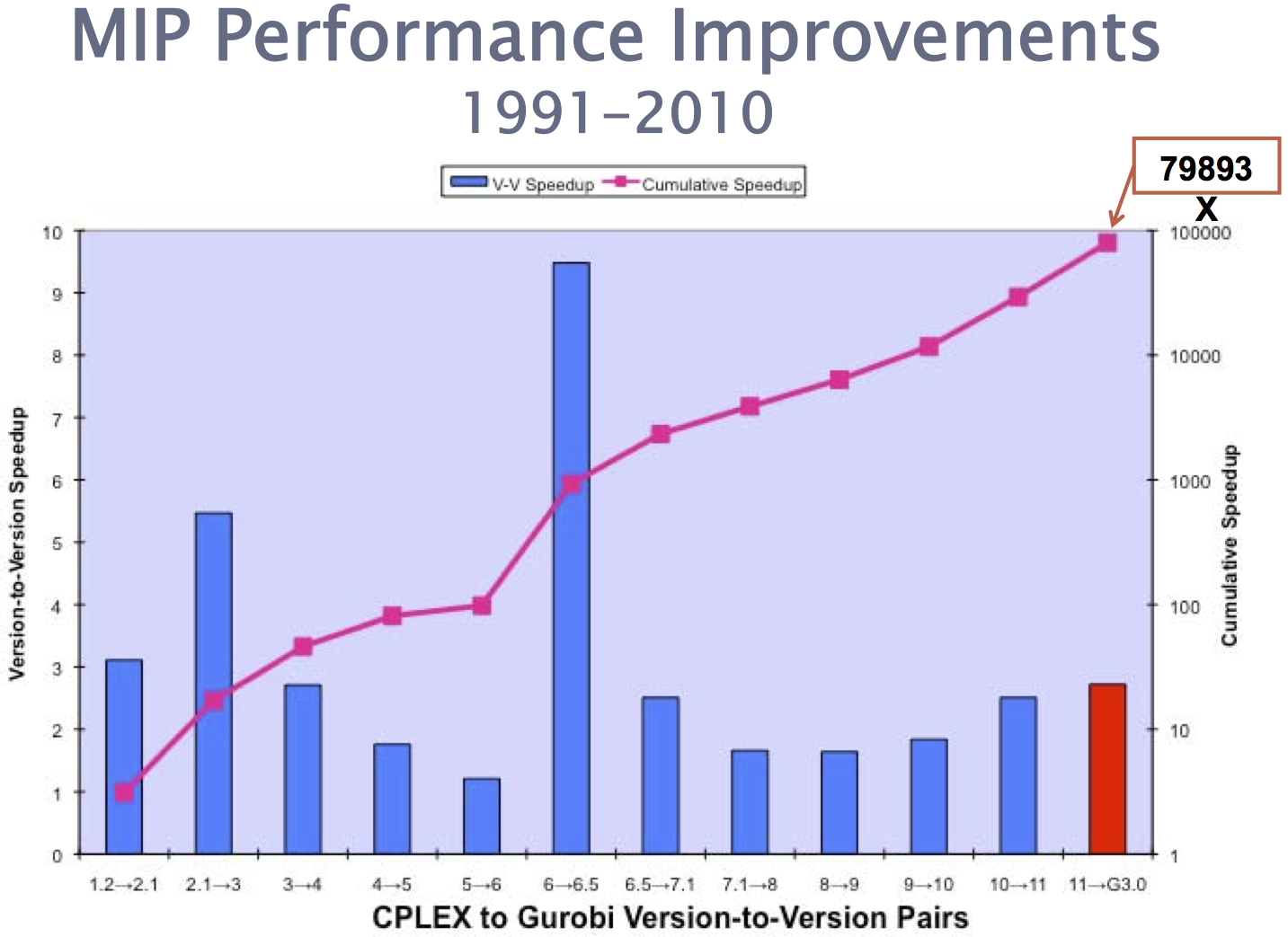
Gomory cuts are still subject of research, since they pose a number of implementation challenges. These cuts suffer from severe numerical issues, mainly because the computation of the inverse matrix requires the division by its determinant.
“In 1959, […] We started to experience the unpredictability of the computational results rather steadily” (Gomory, see [4]).”
A recent paper by Cornuejols, Margot, and Nannicini deals with some of these issues [2].
If you like to learn more about how the basis are computed in the CPLEX LP solver, there is very nice paper by Bixby [3]. The paper explains different approaches to get the first basic feasible solution and gives some hints of the CPLEX implementation of that time, i.e., 1992. Though the paper does not deal with Gomory cuts directly, it is a very pleasant reading.
To conclude, for those of you interested in Optimization Stories there is a nice chapter by G. Cornuejols about the Ongoing Story of Gomory Cuts [4].
References
-
C.H. Papadimitriou, K. Steiglitz. Combinatorial Optimization: Algorithms and Complexity. 1998. [book]
-
G. Cornuejols, F. Margot and G. Nannicini. On the safety of Gomory cut generators. Submitted in 2012. Mathematical Programming Computation, under review. [preprint]
-
R.E. Bixby. Implementing the Simplex Method: The Initial Basis. Journal on Computing vol. 4(3), pages 267–284, 1992. [abstract]
-
G. Cornuejols. The Ongoing Story of Gomory Cuts. Documenta Mathematica - Optimization Stories. Pages 221-226, 2012. [preprint]