Two years ago, I started to study Computational Optimal Transport (OT), and, now, it is time to wrap up informally the main ideas by using an Operations Research (OR) perspective with a Machine Learning (ML) motivation.
Yes, an OR perspective.
Why an OR perspective?
Well, because most of the current theoretical works on Optimal Transport have a strong functional analysis bias, and, hence, the are pretty far to be an “easy reading” for anyone working on a different research area. Since I’m more comfortable with “summations” than with “integrations”, in this post I focus only on Discrete Optimal Transport and on Kantorovich-Wasserstein distances between a pair of discrete measures.
Why an ML motivation?
Because measuring the similarity between complex objects is a crucial basic step in several #machinelearning tasks. Mathematically, in order to measure the similarity (or dissimilarity) between two objects we need a metric, i.e., a distance function. And Optimal Transport gives us a powerful similarity measure based on the solution of a Combinatorial Optimization problem, which can be formulated and solved with Linear Programming.
The main Inspirations for this post are:
- My current favorite tutorial is Optimal Transport on Discrete Domains, by Justin Solomon.
- Two years ago, I started to study this topic thanks to Giuseppe Savaré, and I wrote this post by looking also to his set of slides. He has several interesting papers and you can look at his publications list.
- For a complete overview of this topic look at the Computational Optimal Transport book, by Gabriel Peyré and Marco Cuturi. These two researchers, together with Justin Solomon, where among the organizers of two #NeurIPS workshops, in 2014 and in 2017, on Optimal Transport and Machine Learning.
- For a broader history of Combinatorial Optimization till 1960, see this manuscript by Alexander Schrijver.
DISCLAIMER 1: This is a long “ongoing” post, and, despite my efforts, it might contain errors of any type. If you have any suggestion for improving this post, please (!), let me know about: I will be more than happy to mention you (or any of your avatars) in the acknowledgement section. Otherwise, if you prefer, I can offer you a drink, whenever we will meet in real life.
DISCLAIMER 2: I wrote this post while reading the book Ready Player One, by Ernest Cline.
DISCLAIMER 3: I’m recruiting postdocs. If you like the topic of this post and you are looking for a postdoc position, write me an email.
Similarity measures and distance functions
A metric is a function, usually denoted by , between a pair of objects belonging to a space :
Given any triple of points , the conditions that must satisfy in order to be a metric are:
- (non negativity)
- (identity of indiscernibles)
- (symmetry)
- (triangle inequality or subadditivity)
If the space is , then are vectors of elements, and the most common distance is indeed the Euclidean function
where is the -th component of the vector . Clearly, the algorithmic complexity of computing (in finite precision) this distance is linear with the dimension of .
QUESTION: What if we want to compute the distance between a pair of clouds of points defined in ?
If we want to compute the distance between the two vectors, that represent the two clouds of points, we need to define a distance function.
Let me fix the notation first. If is a vector, then is the -th element. Suppose we have two matrices and with elements, which represent points in . We denote by the -th row of matrix , and by the -th element of row . Indeed, the rows and of the two matrices give the coordinates and of the two corresponding points.
Whenever , a simple choice is to consider the Minkowski Distance, which is a metric for normed vector spaces:
where typical values of are:
- (Manhattan distance)
- (Euclidean distance, see above)
- (Infinity distance)
We have also the Minkowski norm, that is a function
computed as
Whenever , we have to consider a more general distance function:
such that the relations (1)-(4) are satisfied. We could use as distance function any matrix norm, but, to begin with, we can use the Minkowski distance twice in cascade as follows.
- First, we compute the distance between a pair of points in , which we call the ground distance, using , with . By applying this function to all the pairs of points, we get a vector of non-negative values:
- Second, we apply the Minkowski norm to the vector .
Composing these two operations, we can define a distance function between a pair of vectors of points (i.e., pair of matrices) as follows:
Note that for , we get
which is the Frobenius Norm of the element wise difference .
The main drawback of this distance function is that it implicitly relies on the order (position) of the single points in the two input vectors: any permutation of one (or both) of the two vectors will yield a different value of the ground distance. This happens because the distance function between the two input vectors considers only “interactions” between the -th pair of points stored at the same -th position in the two vectors.
IMPORTANT. Here is where Discrete Optimal Transport comes into action: it offers an alternative distance function based on the solution of a Combinatorial Optimization problem, which is, in the simplest case, formulated as the following Linear Program:
If you have a minimal #orms background at this point you should have recognized that this problem is a standard Assignment Problem: we have to assign each point of the first vector to a single point of the second vector , in such a way that the overall cost is minimum. From an optimal solution of this problem, we can select among all possible permutations of the rows of , the permutation that gives the minimal value of the Frobenius norm.
Whenever the ground distance is a metric, then is a metric as well. In other terms, the optimal value of this problem is a measure of distance between the two vectors, while the optimal values of the decision variables gives a mapping from the rows of to the rows of (in OT terminology, an optimal plan). This is possible because the LP problem has a Totally Unimodular coefficient matrix, and, hence, every basic optimal solution of the LP problem has integer values.
WAIT, LET ME STOP HERE FOR A SECOND!
I am being too technical, too early. Let me take a step back in History.
Once Upon a Time: from Monge to Kantorovich
The History of Optimal Transport is quite fascinating and it begins with the Mémoire sur la théorie des déblais et des remblais by Gaspard Monge (1746-1818). I like to think of Gaspard as visiting the Dune of Pilat, near Bordeaux, and then writing his Mémoire while going back to home… but this is only my imagination. Still, particles of sand give me the most concrete idea for passing from a continuous to a discrete problem.

In his Mémoire, Gaspard Monge considered the problem of transporting “des terres d’un lieu dans un autre” at minimal cost. The idea is that we have first to consider the cost of transporting a single molecule of “terre”, which is proportional to its weight and to the distance from its initial and final position. The total cost of transportation is given by summing up the transportation cost of each single molecule. Using the Lex Schrijver’s words, Monge’s transportation problem was camouflaged as a continuous problem.
The idea of Gaspard is to assign to each initial position a single final destination: it is not possible to split a molecule into smaller parts. This unsplittable version of the problem posed a very challenging problem where “the direct methods of the calculus of variations fail spectacularly” (Lawrence C. Evans, see link at page 5). This challenge stayed unsolved until the work of Leonid Kantorovich (1912-1986).
Curiously, Leonid did not arrive to the transportation problem while studying directly the work of Monge. Instead, he was asked to solve an industrial resource allocation problem, which is more general than Monge’s problem. Only a few years later, he reconsidered his contribution in terms of the continuous probabilistic version of Monge’s transportation problem. However, I am unable to state the true technical contributions of Leonid with respect to the work of Gaspard in a short post (well, honestly, I would be unable even in an infinite post), but I recommend you to read the Long History of the Monge-Kantorovich Transportation Problem.
Anyway, I have pretty clear the two main concepts that are the foundations of the work by Kantorovich:
- RELAXATION: He relaxes the problem posed by Gaspard and he proves that an optimal solution of the relaxation equals an optimal solution of the original problem (Here is the link to the very unofficial soundtrack of his work: “Relax, take it easy!”). Indeed, Leonid relaxed formulation allows each molecule to be split across several destinations, differently from the formulation of Monge. In OR terms, he solves a Hitchcock Problem, not an Assignment Problem. For more details, see Chapter 1 of the Computational Optimal Transport.

- DUALITY: Leonid uses a dual formulation of the relaxed problem. Indeed, he invented the dual potential functions and he sketched the first version of dual simplex algorithm. Unfortunately, I studied Linear Programming duality without having an historical perspective, and hence duality looks like obvious, but at the time is was clearly a new concept.
For the records, Leonid Kantorovich won the Nobel Prize, and his autobiography merits to be read more than once.
Well, I have still so much to learn from the past!
Two Fields medal winners: Alessio Figalli and Cedric Villani
If you think that Optimal Transport belongs to the past, you are wrong!
Last summer (2018), in Rio de Janeiro, Alessio Figalli won the Fields Medal with this citation:
“for his contributions to the theory of optimal transport, and its application to partial differential equations, metric geometry, and probability”
Alessio is not the first Fields medalist who worked on Optimal Transport. Already Cedric Villani, who wrote the most cited book on Optimal Transport [1], won the Fields Medal in 2010. I strongly suggest you to look any of his lectures available on Youtube. And … do you know that Villani spent a short period of time during his PhD in my current Math Dept. at University of Pavia?
As an extra bonus, if you don’t know what a Fields Medal is, you can have Robin Williams to explain the prize in this clip taken from Good Will Hunting.
Discrete Optimal Transport and Linear Programming
It is time of being technical again and to move from the Monge assignment problem, to the Kantorovich “relaxed” transportation problem. In the assignment model presented above, we are implicitly considering that all the positions are occupied by a single molecule of unitary weight. If we want to consider the more general setting of Discrete Optimal Transport, we need to consider the “mass” of each molecule, and to formulate the problem of transporting the total mass at minimum cost. Before presenting the model, we define formally the concept of a discrete measure and of the cost matrix between all pairs of molecule positions.
DISCRETE MEASURES: Given a of vector of positions , and given the Dirac delta function, we can define the Dirac measures as
Given a vector of weights , one associated to each element of , we can define the discrete measure as
Note the is a function of type: , for any subset of . The vector is called the support of the measure . In Computer Science terms, a discrete measure is defined by a vector of pairs, where each pair contains a positive number (the measured value) and its support point (the location where the measure occurred). Note that is a (small?) vector storing the coordinates of the -th point.
COST MATRIX: Given two discrete measures and , the first with support and the second with support , we can define the following cost matrix:
where is a distance function, such as, for instance, the Minkowski distance defined before. Note that has elements, and has elements.
Kantorovich-Wasserstein distances between two discrete measures
At this point, we have all the basic elements to define the Kantorovich-Wasserstein distance function between discrete measures in terms of the solution of a (huge) Linear Program.
INPUT: Two discrete measures and defined on a metric space , and the corresponding supports and , having and elements, respectively. A distance function , which permits to compute the cost .
OUTPUT: A transportation plan and a value of distance of that corresponds to an optimal solution of the following Linear Program:
This Linear Program is indeed a special case of the Transportation Problem, known also as the Hitchcock-Koopmans problem. It is a special case because the cost vector has a strong structure that should be exploited as much as possible.
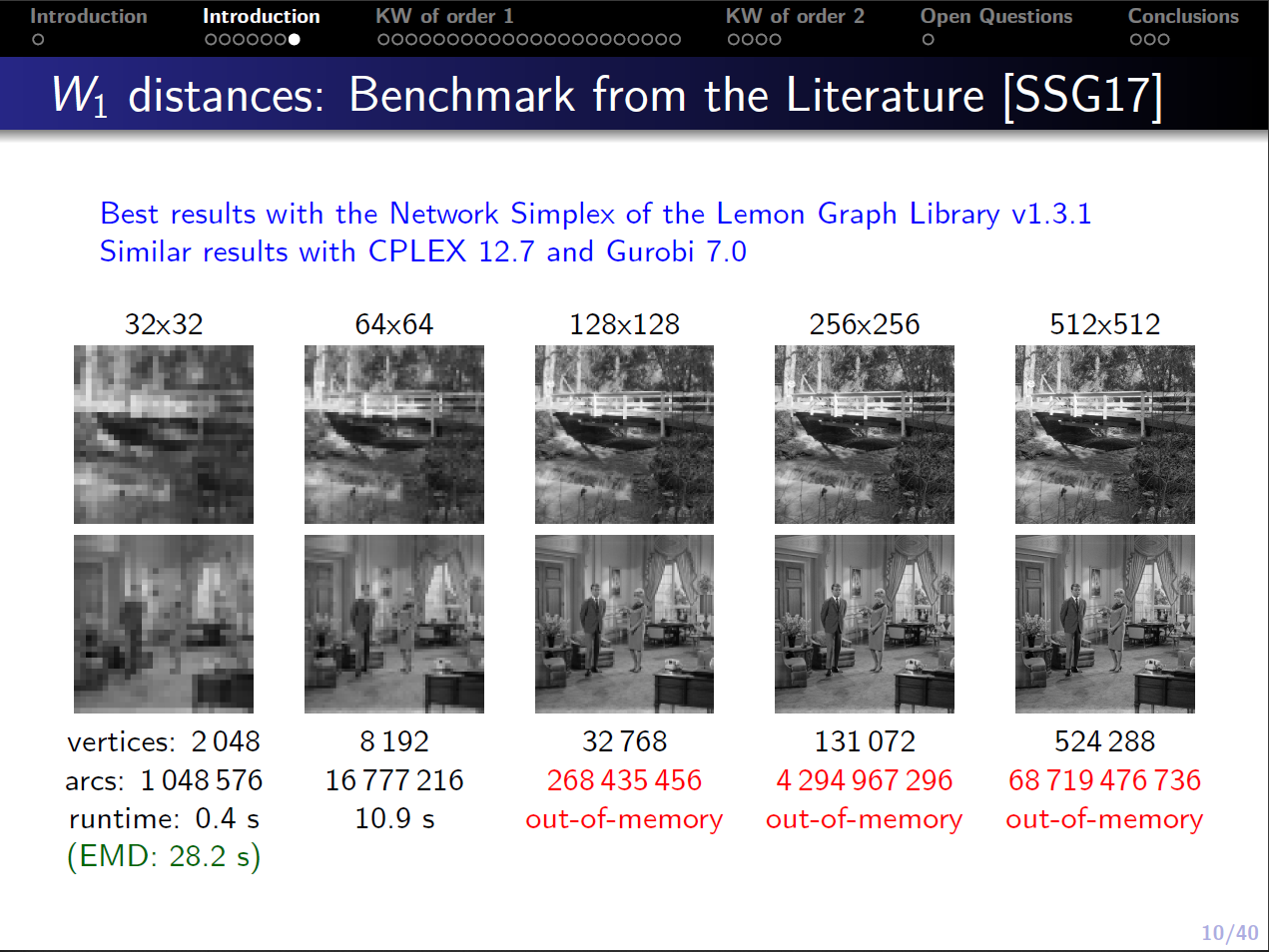
Computational Challenge: While the previous problem is polynomially solvable, the size of practical instances is very large. For instance, if you want to compute the distance between a pair of grey scale images of resolution pixels, you end up with an LP with cost coefficients. Hence, these problems must be handled with care. If you want to see how the solution time and memory requirement scale for grey scale image, please, have a look at the slides of my talk at Aussois (2018).
KANTOROVICH-WASSERSTEIN DISTANCE
Whenever
- The two measure are discrete probability measures, that is, both and (i.e., and belongs to the probability simplex), and,
- The cost vector is defined as the -th power of a distance,
then we define the Kantorovich-Wasserstein distance of order as the following functional:
where the set is defined as:
From a mathematical perspective, the most interesting case is the order , which generalizes the Euclidean distance to discrete probability vectors. Note that in this formulation, the two constraint sets defining could be replaced with equality constraints, since and belongs to the probability simplex. In addition, any Combinatorial Optimization algorithm must be used with care, since all the cost and constraint coefficients are not integer. Note: The power used for the ground distance must not be confused with the order (power) of a Kantorovich-Wasserstein distance.
EARTH MOVER DISTANCE
A particular case of the Kantorovich-Wasserstein distance very popular in the Computer Vision research community, is the so-called Earth Mover Distance (EMD) [2], which is used between a pair of -dimensional histograms obtained by preprocessing the images of interest. In this case, (i) we have , (ii) we do not require the discrete measures to belong to the probability simplex, and (iii) we do not even require that the two measures are balanced, that is, . In Optimal Transport terminology, the Earth Mover Distance solves an unbalanced optimal transport problem. For the EMD, the feasibility set is replaced by the set:
The cost function is taken with the order :
The most used function is the Minkowski distance induced by the norm.
WORD MOVER DISTANCE
A very interesting application of discrete optimal transport is the definition of a metric for text documents [3]. The main idea is, first, to exploit a word embedding obtained, for instance, with the popular word2vec neural network [4], and, second, to formulate the problem of “transporting” a text document into another at minimal cost.
Yes, but … how we compute the ground distance between two words?
A word embedding associates to each word of a given vocabulary a vector of . For the pre-trained embedding made available by Google at this archive, which contains the embedding of around 3 millions of words, is equals to 300. Indeed, given a vocabulary of words and fixed a dimension , a word embedding is given by a matrix of dimension : Row gives the -dimensional vector representing the word embedding of word .
In this case, instead of having discrete measures, we deal with normalized bag-of-words (nBOW), which are vector of , where denotes the number of words in the vocabulary. If a text document contains times the word , then . At this point is clear that the ground distance between a pair of words is given by the distance between the corresponding embedding vectors in , that is, given two words and , then
Finally, given two text documents and , we can formulate the Linear Program that gives the Word Mover Distance as:
where the set is defined as:
If you are serious reader, and you are still reading this post, then it is clear that the Word Mover Distance is exactly a Kantorovich-Wasserstein distance of order 1, with an Euclidean ground distance. If you are interested in the quality of this distance when used within a nearest neighbor heuristic for a text classification task, we refer to [3]. (While writing this post, I started to wonder how would perform a WMD of order 2, but this is another story…)
Interesting Research Directions
The following are the research topics I am interested in right now. Each topic deserves its own blog post, but let me write here just a short sketch.
-
Computational Challenges: The development of efficient algorithms for the solution of Optimal Transport problems is an active area of research. Currently, the preferred (heuristic) approach is based on so-called regularized optimal transport, introduced originally in [5]. Indeed, regularized optimal transport deserves its own blog post. In two recent works, together with my co-authors, we tried to revive the Network Simplex for two special cases: Kantorovich-Wasserstein distances of order 1 for -dimensional histograms [6] and Kantorovich-Wasserstein distances of order 2 for decomposable cost functions [7]. The second paper was presented as a poster at NeurIPS2018. (If you ever read any of the two papers, please, let me know what you think about them)
-
Unbalanced Optimal Transport: The computation of Kantorovich-Wasserstein distance for pair of unbalanced discrete measures is very challenging. Last year, a brilliant math student finished a nice project on this topic, which I hope to finalize during the next semester.
-
Barycenters of Discrete Measures: The Kantorovich-Wasserstein distance can be used to generalize the concept of barycenters, that is, the problem of finding a discrete measure that is the closest (in Kantorovich terms) to a given set of discrete measures. The problem of finding the barycenter can be formulated as a Linear Program, where the unknowns (the decision variables) are both the transport plan and the discrete measure representing the barycenter. For instance, the following images, taken from our last draft paper, represents the barycenters of each of the 10 digits of the MNIST data set of handwritten images (each image is the barycenter of other images).

- Distances between Discrete Measures defined on different metric spaces: This topic is at the top of my 2019 resolutions. There are a few papers by Facundo Mémoli on this topic, which are based on the so-called Gromov-Wasserstein distance and that requires the solution of a Quadratic Assignment Problem (QAP).
Now, it’s time to close this post with final remarks.
Optimal Transport: A brilliant future?
Given the number and the quality of results achieved on the Theory of Optimal Transport by “pure” mathematicians, it is the time to turn these theoretical results into a set of useful algorithms implemented in efficient and scalable solvers. So far, the only public library I am aware of is POT: Python Optimal Transport.
On Medium, C.E. Perez claims that Optimal Transport Theory (is) the New Math for Deep Learning. In his short post, he explains how Optimal Transport is used in Deep Learning algorithms, specifically in Generative Adversarial Networks (GANs), to replace the Kullback-Leibler (KL) divergence.
Honestly, I do not have a clear idea regarding the potential impact of Kantorovich distances on GANs and Deep Learning in general, but I think there are a lot of research opportunities for everyone with a strong passion for Computational Combinatorial Optimization.
And you, what do you think about the topics presented in this post?
As usual, I will be very happy to hear from you, in the meantime…
GAME OVER
Acknowledgement
I would like to thank Marco Chiarandini, Stefano Coniglio, and Federico Bassetti for constructive criticism of this blog post.
References
-
Villani, C. Optimal transport, old and new. Grundlehren der mathematischen Wissenschaften, Vol.338, Springer-Verlag, 2009. [pdf]
-
Rubner, Y., Tomasi, C. and Guibas, L.J., 2000. The earth mover’s distance as a metric for image retrieval. International journal of computer vision, 40(2), pp.99-121. [pdf]
-
Kusner, M.J., Sun, Y., Kolkin, N.I., Weinberger, K.Q. From Word Embeddings To Document Distances. Proceedings of the 32 nd International Conference on Machine Learning, Lille, France, 2015. [pdf]
-
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S. and Dean, J., 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119). [pdf]
-
Cuturi, M., 2013. Sinkhorn distances: Lightspeed computation of optimal transport. In Advances in neural information processing systems (pp. 2292-2300). [pdf]
-
Bassetti, F., Gualandi, S. and Veneroni, M., 2018. On the Computation of Kantorovich-Wasserstein Distances between 2D-Histograms by Uncapacitated Minimum Cost Flows. arXiv preprint arXiv:1804.00445. [pdf]
-
Auricchio, G., Bassetti, F., Gualandi, S. and Veneroni, M., 2018. Computing Kantorovich-Wasserstein Distances on d-dimensional histograms using (d+1)-partite graphs. NeurIPS, 2018.[pdf]